
Predicting the Sale Price of Bulldozers Using Machine Learning
This project focuses on developing a machine learning model to predict bulldozer sale prices, a classic regression task. The aim is to fine-tune this model to achieve the lowest RMSLE, ensuring accurate and reliable price forecasts.
Our project analyzes a time series dataset from Kaggle, encompassing historical sales data of bulldozers, which includes key details such as model type, size, and sale date. The dataset is divided into three parts:
-
Train.csv: Contains sales records up to 2011 with over 400,000 instances and more than 50 attributes, including the target variable 'SalePrice'.
-
Valid.csv: Features sales data from January 1, 2012, to April 30, 2012, with nearly 12,000 examples that match the Train.csv structure.
-
Test.csv: Offers sales records from May 1, 2012, to November 2012, also with nearly 12,000 instances, but omits the 'SalePrice' attribute, which our model aims to predict.
The initial steps are taken to import and prepare the bulldozer sales data for modeling.
-
Importing Libraries
Essential Python libraries are imported for data manipulation and visualization.
-
Loading Data
The combined training and validation dataset is loaded into a DataFrame. The low_memory=False parameter is used to efficiently load data without worrying about memory usage, which is useful for large datasets.
-
Data Inspection
The commands df.info() and df.isna().sum() are utilized to gain initial insights into the DataFrame, with df.info() providing a summary of data types and non-null counts for each column.
Output:
df.isna().sum() calculates the total missing values across different columns.
Output:
-
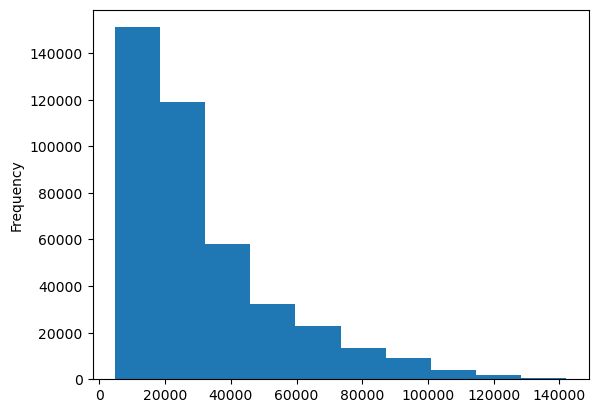
Initial Data Visualization
A histogram of the 'SalePrice' column is generated to understand its distribution. This helps in getting a sense of the common price ranges and the overall spread of the sale prices.
Preparing and Analyzing Time Series Data
This code snippet demonstrates the steps taken to handle time series data in a machine learning project aimed at predicting bulldozer sale prices.
-
Re-importing Data with Date Parsing
The dataset is reloaded using pandas.read_csv(), but this time with an additional parameter: parse_dates=["saledate"]. This instructs Pandas to interpret the 'saledate' column as dates and convert them into Python datetime objects.
-
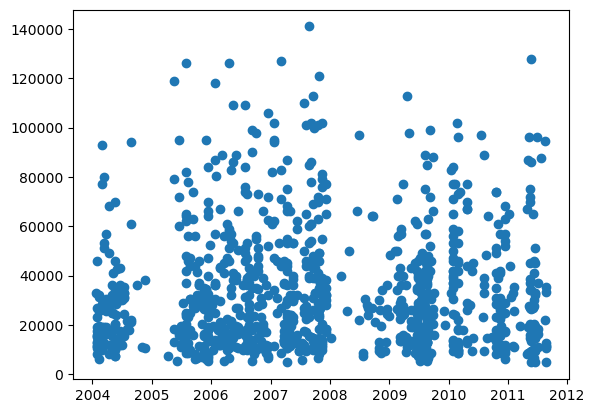
Initial Visualization of Time Series Data
A scatter plot is created using matplotlib.pyplot . The plot visualizes the relationship between 'saledate' and 'SalePrice' for the first 1000 entries. This visualization helps in understanding how sale prices might vary over time, which is crucial in time series analysis.
-
Sorting the DataFrame by Date
The DataFrame, df is sorted based on the 'saledate' column using df.sort_values(). The by=["saledate"] argument specifies the column to sort by. Setting inplace=True modifies the original DataFrame, and ascending=True sorts the dates in chronological order.
Sorting by date is a critical step in time series analysis, as it ensures that the data is in the correct sequence for further analysis and modeling, which often rely on the order of data points.
-
Make a copy of the original DataFrame
To ensure the integrity of the original DataFrame is maintained while we manipulate the data, we will create a copy of it. By working with this duplicate, we can freely modify and experiment with the data, while still preserving the original DataFrame for future reference or additional analysis.
DateTime Feature Engineering for Bulldozer Dataset
In this section, the code enriches the df_tmp DataFrame by extracting and adding several datetime-related features from the 'saledate' column. This process helps in breaking down the date information into more specific components that can be useful for analysis and modeling.
-
Extracting DateTime Features
-
Removing the Original 'saledate' Column
This line removes the original 'saledate' column from df_tmp as its data has been decomposed into more specific features. The inplace=True argument modifies the DataFrame in place.
Exploratory Data Analysis
In this section, the code performs Exploratory Data Analysis (EDA) on the DataFrame, which is an essential step in understanding the dataset's structure and preparing it for modeling.
-
Checking Data Types and Missing Categories
The code below is used to display a concise summary of the DataFrame, providing information about the data types of each column, the number of non-null values, and the overall memory usage. It's an essential step to identify columns with missing values and to understand the data types (numerical, categorical, etc.) present in the dataset.
Output:
-
Checking for Missing Values
This command calculates the total number of missing values in each column of the DataFrame. Understanding where missing values exist is crucial for effective data preprocessing, as it may require handling these missing values through techniques like imputation or exclusion, depending on the context and significance of the data.
Output:
-
Convert Strings to Categories
This section of the code deals with converting string data types to categorical types, which is a common preprocessing step in machine learning, especially for models that require numerical input.
Identifying String Columns
The first loop iterates through each column in df_tmp. It checks if the column data type is a string using pd.api.types.is_string_dtype(content).
Output:
Identifying Object Columns
The second loop is similar to the first but checks for columns of object data. It prints the label of each object type column and increments.
Output:
Converting Objects to Categories
The third loop goes through each column again and converts columns with object data types to categorical types using content.astype("category").cat.as_ordered().
After conversion, you can access the numerical codes of these categories, as shown with df_tmp.state.cat.codes
Output:
Our dataset is now fully categorized, enabling the conversion of these categories into numerical form. However, there are still some missing values that need to be addressed.
-
Saving Preprocessed Data
Exporting the Current DataFrame
The current state of the DataFrame, which has undergone preprocessing, is saved to a CSV file. This is achieved using the to_csv method. index=False is specified to ensure that the DataFrame's index is not included in the exported file, which can be important for maintaining data consistency when the file is read back into a DataFrame.
Importing the Preprocessed Data
The preprocessed data, now stored in the CSV file, is re-imported back into a DataFrame (df_tmp). This step is useful for scenarios where the preprocessing script is run separately from the analysis or modeling script. The low_memory=False parameter is used to efficiently handle the data loading process, especially useful when dealing with large datasets.
Our updated DataFrame, enriched with new columns, still has missing values, which can be identified using df_tmp.isna().sum().
Output:
Inference: The output indicates that while several columns in the DataFrame, such as 'SalesID', 'SalePrice', 'MachineID', 'ModelID', 'datasource', 'YearMade', and 'fiModelDesc', have no missing values, others have a significant number of missing entries. Notably, 'auctioneerID' has 20,136 missing values, 'MachineHoursCurrentMeter' has 265,194, 'UsageBand' is missing 339,028 entries, 'fiSecondaryDesc' lacks 140,727 values, and 'fiModelSeries' is missing in 354,031 cases.
-
Filling Missing Values
Now, after identifying and analyzing the different data types within our DataFrame, we focus on addressing the missing values specifically in the numerical columns.
Identifying Numerical Columns
The first loop iterates through each column in df_tmp. It checks if the column data type is numeric using pd.api.types.is_numeric_dtype(content). If a column is of numeric type, its label is printed. This step is crucial for identifying which columns are numerical and may contain missing values.
Detecting Missing Numerical Values
The second loop is similar to the first but includes an additional check to see if any numeric columns have null values. This is done using pd.isnull(content).sum(), which sums up the null (missing) values in each numeric column. Columns with missing values are printed, helping to pinpoint where data imputation is needed.
Output:
Filling Missing Numerical Values
The third loop goes through the numeric columns again. If a column has missing values, two actions are taken. A binary (True/False) column is added to df_tmp, named [label]_is_missing, to indicate whether data was missing in that column. This approach retains information about the presence of originally missing data, which could be significant for analysis and modeling.
Missing values in numeric columns are filled with the median of that column, using content.fillna(content.median()). The median is a robust measure of central tendency that is less affected by outliers, making it a good choice for imputing missing values.
-
Transforming Categorical Data to Numbers
Similarly, we apply the same approach to the categorical variables in the DataFrame, getting them ready for machine learning analysis.
Identifying Non-Numeric Columns
The first loop iterates through each column in df_tmp to identify non-numeric columns using if not pd.api.types.is_numeric_dtype(content). It prints the label of each non-numeric column and counts them. The total count of non-numeric columns is printed at the end, providing an overview of how many categorical columns need processing.
Output:
Converting Categorical Variables to Numeric
The second loop processes each non-numeric column. For each such column, a binary column is added to df_tmp, named [label]_is_missing, to track whether the original column had any missing values. The categorical data is converted into numerical codes using pd.Categorical(content).codes. The +1 is added because Pandas encodes missing categories as -1. Adding 1 shifts all the codes up, ensuring that missing values are represented as 0 (which is more typical in numerical datasets).
Checking for Remaining Missing Values
After processing, df_tmp.isna().sum() checks if there are any more missing values across the entire DataFrame.
Output:
Splitting Data into Train and Validation Sets
In dealing with our time series problem, the approach to dividing the data into training, validation, and test sets is guided by the timeline of events. The Kaggle data page indicates that the validation and test sets are segregated based on specific dates, which aligns well with the nature of our project where we aim to use historical data to predict future outcomes.
For this reason, a standard random split using a method like train_test_split() wouldn’t be appropriate. Instead, we categorize our data into different sets based on the date of occurrence of each data point.
In our scenario, this translates to:
-
The training set consists of all data samples up until the year 2011.
-
The validation set includes all samples from January 2012.
-
The test set encompasses samples from May 1, 2012, to November 2012.
-
Inspecting Sale Year Distribution
The df_tmp.saleYear.value_counts() command is used to inspect the distribution of data across different years. This helps in understanding how the data is spread over time, which is crucial for time series problems.
Output:
-
Splitting into Training and Validation Sets
The dataset df_tmp is split into two subsets based on the year of sale (saleYear). df_val is created to include all samples where saleYear is 2012, thus forming the validation set. df_train includes all samples where saleYear is not 2012, which becomes the training set.
Output:
-
Splitting Data into Features (X) and Target Variable (y):
For the training set, X_train and y_train are created by separating the features and the target variable (SalePrice). X_train contains all columns except SalePrice. y_train contains only the SalePrice column. A similar split is done for the validation set, creating X_valid and y_valid. The shape of these subsets is checked to ensure they are correctly partitioned. The shape (number of rows and columns) is important for verifying that the data is split as intended, with features and target variables correctly aligned in each set.
Output:
Building an Evaluation Function
In the Bluebook for Bulldozers competition on Kaggle, the primary metric for evaluating model performance is the Root Mean Squared Log Error (RMSLE). This choice of metric implies a focus on relative errors (ratios) rather than absolute differences.
Understanding the evaluation metric is crucial for model tuning and interpretation of results. Scikit-Learn, a popular machine learning library, does not have a built-in RMSLE function. However, we can craft one by utilizing Scikit-Learn's mean_squared_log_error (MSLE). The RMSLE can be obtained by taking the square root of MSLE, which is effectively equivalent to applying a logarithmic transformation to the Mean Squared Error (MSE).
Efficient Hyperparameter Tuning with a Training Subset
To accelerate our experimentation process, we'll avoid retraining the entire model each time, as it's a time-consuming task. Instead, our strategy involves selecting a subset from the training set for hyperparameter tuning. This approach allows us to quickly adjust and test different hyperparameters. Once we find the optimal settings, we can then apply them to train the full-scale model. This method strikes a balance between speed and effectiveness in model development.
In this section of the code, adjustments are being made to the RandomForestRegressor model to improve training efficiency, and then the model's performance is evaluated. Here's a breakdown of each step.
-
Instantiating the RandomForestRegressor Model
RandomForestRegressor is initialized with specific parameters. n_jobs=-1 allows the model to use all processors available for parallel training, speeding up the training process. max_samples=10000 limits the maximum number of samples each tree in the forest can see to 10,000. This is a key change aimed at reducing training time. By limiting the number of samples, each tree in the forest has a smaller subset of the data to process, which speeds up the training significantly.
-
Training the Model
The model.fit(X_train, y_train) command trains the RandomForestRegressor on the training data. This step involves the model learning the patterns in the data to make future predictions.
-
Evaluating the Model
The show_scores(model) function is called to evaluate the trained model. This custom function likely computes and returns various performance metrics such as Mean Absolute Error (MAE), Root Mean Squared Log Error (RMSLE), and the R-squared value (R^2) for both the training set and the validation set.
Output:
These metrics provide insight into how well the model is performing. For instance, MAE will show the average error in predictions, RMSLE will provide a measure of error adjusted for the scale of the data, and R^2 will indicate the proportion of variance in the dependent variable that is predictable from the independent variables.
Hyperparameter Tuning with RandomizedSearchCV
In this part, hyperparameter optimization for a RandomForestRegressor model is being executed through the use of Scikit-Learn's RandomizedSearchCV. This process involves several key steps as outlined below.
-
Setting up the Hyperparameter Grid
A dictionary of hyperparameters for RandomForestRegressor is created. The number of trees in the forest, set to range from 10 to 100 in steps of 10. The maximum depth of the trees, with options including 'None' (no limit) and fixed depths of 3, 5, and 10. The minimum number of samples required to split an internal node, with values ranging from 2 to 20 in steps of 2. The number of features to consider when looking for the best split; options include 0.5, 1.0, and "sqrt". The maximum number of samples to draw from X to train each base estimator, set to 10000.
-
Initializing and Configuring RandomizedSearchCV
An instance of RandomizedSearchCV is created, named rs_model. The RandomForestRegressor is passed as the estimator, with n_jobs=-1 for parallel processing and random_state=42 for reproducibility.
n_iter=100 denotes that 100 different combinations will be tried.
-
Fitting the RandomizedSearchCV Model
rs_model.fit(X_train, y_train) trains the RandomizedSearchCV model using the training data. This step involves evaluating 100 different parameter combinations and selecting the best one based on cross-validation.
-
Finding the Best Model Hyperparameters
rs_model.best_params_ retrieves the best combination of parameters found during the search.
Output:
-
Evaluating the Tuned Model
The function show_scores(rs_model) is called to evaluate the performance of the model with the best found parameters. This function calculates and returns evaluation metrics for the model.
Output:
Implementing Optimal Hyperparameters in Model Training
This section describes the process of refining a machine learning model by applying the best hyperparameters identified through RandomizedSearchCV. Initially, RandomizedSearchCV was used to experiment with 100 different hyperparameter combinations (as indicated by setting n_iter to 100). This process was conducted on a subset of the data (10,000 examples) to save time, as a full-scale search on the entire dataset would be excessively time-consuming.
The outcome of this tuning process yielded a set of optimal hyperparameters that demonstrated the best performance during the RandomizedSearchCV.
-
Retraining on Full Dataset
The next step involves leveraging these identified hyperparameters to train a new model. This time, however, the training will be conducted on the full dataset to maximize the model's learning and predictive capabilities. Training on the full dataset, as opposed to a subset, should enhance the model's accuracy and generalizability, albeit at the cost of increased computational time.
In the new model instantiation, the max_samples parameter will be reset to its original value to ensure that the model can learn from the entire dataset, rather than just a limited subset.
-
Model Evaluation
The function show_scores takes ideal_model as an argument. It uses this model to make predictions on both the training and validation datasets.
Output:
Predicting Future Sales with the Trained Model
Having successfully trained our model with historical data, the next step is to apply it to the test dataset. This dataset consists of records from May 1, 2012, to November 2012, a period not covered by our training data, which includes data only up to 2011.
-
Reading the Test Dataset
This function call reads a CSV file into a pandas DataFrame. By setting parse_dates to ["saledate"], pandas will automatically parse this column as datetime objects.
-
Creating a Preprocessing Function
To ensure our model can accurately predict outcomes on the test dataset, it's crucial that the test data undergoes the same preprocessing steps as the training data. This standardization is key because the model has learned to make predictions based on the specific format, structure, and transformations applied to the training data.
To facilitate this, we'll develop a function that encapsulates all the preprocessing steps. This function will take raw test data as input and output data in the format suitable for the model, ensuring consistency and reducing the risk of errors in data handling.
The next step involves applying this function to the test dataset, ensuring it is in the same format as our training dataset for consistency.
-
Identifying Column Differences
The code first identifies differences in columns between the training dataset and the test dataset. This is done using set operations: set(X_train.columns) - set(df_test.columns). This operation finds any columns that are present in X_train but not in df_test.
Output:
-
Manually Adjusting the Test Dataset
The code snippet df_test["auctioneerID_is_missing"] = False adds a new column auctioneerID_is_missing to df_test. This step corrects for a column that exists in the training data but is missing in the test data. The column is filled with False, indicating that this particular feature (auctioneerID) is not missing in the test data.
-
Aligning Column Order
The order of columns in df_test is aligned with that of X_train using df_test = df_test[X_train.columns]. This step ensures that the columns in the test dataset are in the exact same order as in the training dataset. This alignment is crucial because the model has learned to predict based on the order of features as they appear in the training set.
-
Making Predictions on Test Data
Finally, the ideal_model (a previously trained and tuned model) is used to make predictions on the test dataset. The model applies what it has learned from the training data to this new, unseen data, outputting predictions for the SalePrice.
The predictions made by the model are being formatted into a specific structure.
Output:
Feature Importance
Having developed a model capable of making predictions, it's natural to wonder which aspects of the data most significantly influence these predictions. This curiosity is addressed by examining feature importance.
Feature importance aims to identify the specific data attributes that play a crucial role in predicting the target variable (in this case, SalePrice). It's about understanding which factors the model considers most influential in determining the outcome.
For our scenario, we're interested in discovering which attributes of bulldozer sales are most impactful in forecasting their sale price, according to the model's learned patterns. To uncover this, we look at the feature_importances_ attribute of our RandomForestRegressor. This attribute helps us understand the relative importance of each feature in the context of the model's predictions.
Output:
Continuing from our previous discussion on feature importance, the next step involves visually representing this data. To achieve this, we define a helper function called plot_features. This function is specifically designed to create a visual representation of the feature importances in our ideal_model, which is our finely tuned machine learning model.
Output:
